 Fot. 1. Wymiana modułu 100 kW w systemie EcoPower DPA PLUS
Fot. 1. Wymiana modułu 100 kW w systemie EcoPower DPA PLUSW tym artykule skupię się na sektorze Data Center. Jest on mi najbliższy zawodowo, a jeśli chodzi o niezawodność, to właśnie ten segment rynku stawia najwyższe wymagania. Nie oznacza to, że wnioski mają jedynie zastosowanie w serwerowni, ponieważ system zasilania np. sali operacyjnej jest równie istotnym, jeśli nawet nie bardziej krytycznym systemem, w którym należy stosować tak samo wysokie wymagania.
Podstawową i najważniejsza zasadą, od której należy wyjść przy projektowaniu systemów elektroenergetycznych (jak również innych systemów, ale w tym artykule skoncentruję się na zasilaniu gwarantowanym), jest niezawodność.
 Rys. 2. UPS-y monoblokowe typ Tajfun Eco MAXI w pracy równoległej
Rys. 2. UPS-y monoblokowe typ Tajfun Eco MAXI w pracy równoległejCzym jest tak naprawdę niezawodność? Często mylona jest ona z pojęciem prawdopodobieństwa awarii, tzn. im rzadziej występują awarie systemu UPS, tym bardziej niezawodny jest system. Otóż nie do końca.
Prawdopodobieństwo awarii możemy (i powinniśmy!) minimalizować między innymi poprzez wybór rozwiązań renomowanych producentów prezentujących najwyższą jakość wykonania, poprzez właściwy i regularny serwis, wymiany prewencyjne elementów eksploatacyjnych oraz właściwy monitoring urządzeń.
Jeśli zastosować rachunek prawdopodobieństwa i niezawodności, oczywiste staje się, że systemem, w którym najrzadziej dochodzi do awarii, będzie pojedynczy monoblokowy UPS, a system nadmiarowy będzie miał wyższe prawdopodobieństwo awarii, ponieważ będzie ono iloczynem prawdopodobieństwa awarii każdej jednostki UPS. Niezawodność powinna być jednak rozpatrywana w zakresie całego systemu, funkcjonalności i stawianych mu celów. Jeśli mamy serwerownię, która powinna pracować nieprzerwanie przez cały rok 24/7, powinniśmy zaprojektować system elektroenergetyczny, który będzie to umożliwiał – nawet w przypadku awarii, prowadzenia prac serwisowych, czy też naprawy. Awaria jednego z podsystemów nie powinna mieć wpływu na poprawność funkcjonowania całego systemu. Przykładowo: dysponujemy systemem UPS, który umożliwia pracę z falownika, pracę na by-passie elektronicznym (tryb ECO) i pracę z baterii. Jeśli w takim systemie dojdzie do awarii UPS, a mimo to nadal mamy dostęp do wszystkich funkcji gwarantujących poprawną i bezpieczną pracę, to mamy do czynienia z systemem niezawodnym. Należy poszukiwać systemów niezawodnych o wysokiej jakości wykonania – bo systemy całkowicie bezawaryjne po prostu nie istnieją.
Czym jest wspomniany już w tytule pojedynczy punkt awarii? Pojedynczy punkt awarii – z angielskiego Single Point of Failure (w skrócie SPOF) jest elementem, którego awaria spowoduje przerwanie działania całego systemu lub utratę podstawowych funkcji. Dlaczego użyłem w odniesieniu do niego porównania do przyczajonego tygrysa? Ponieważ – podobnie jak dzikie zwierzę – taki system jest nieobliczalny i może „zaatakować” w dowolnym momencie. Możemy próbować go oswoić, ale musimy się pogodzić z realnym, nie dającym się całkowicie wyeliminować zagrożeniem.
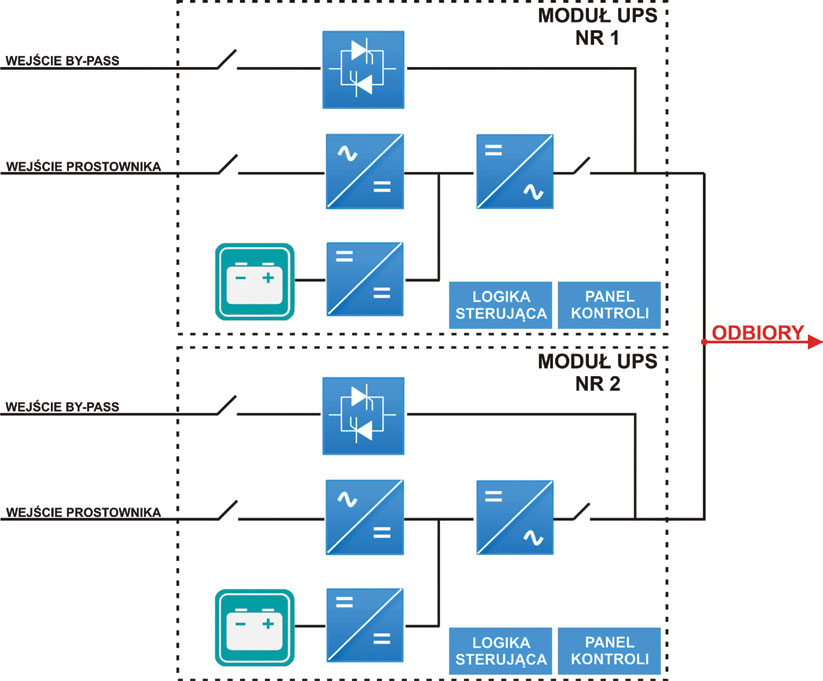 Rys. 3. Schemat systemu modułowego bez pojedyńczych punktów awarii
Rys. 3. Schemat systemu modułowego bez pojedyńczych punktów awariiPoniżej omówię różne koncepcje zasilania pozwalające uniknąć pojedynczych punktów awarii.
Systemy monoblokowe redundantne
Jest to najpopularniejszy sposób zwiększania niezawodności systemu poprzez pracę równoległą – w systemie UPS pracuje zwykle jedna jednostka nadmiarowa (n+1), co w przypadku awarii jednego z komponentów gwarantuje ciągłość pracy systemu. Każdy z UPS-ów powinien być przystosowany do autonomicznej niezależnej pracy.
Przykładowo nasze zapotrzebowanie na moc wynosi 100 kW, nasz system redundantny może się składać z dwóch jednostek UPS o mocy 100 kW.
Minusem takich systemów jest zajmowana powierzchnia (trzeba przewidzieć dodatkowe miejsce na rozbudowę w przyszłości), a także konieczność wykonywania prac kablowych, instalacyjnych i przyłączeniowych na działającym systemie. Naprawa takich systemów jest trudna i czasochłonna – wykonywana zwykle w miejscu instalacji.
Pojawiające się pojedyncze punkty awarii przy tego rodzaju architekturze (choć niekoniecznie) to wspólny system baterii oraz centralny by-pass – oba przypadki mogą prowadzić do groźnych awarii. Omówię je za chwilę na przykładzie systemów modułowych.
Systemy modułowe redundantne
Podobnie jak w przypadku systemów monoblokowych tworzy się je z autonomicznych zasilaczy UPS mających swój własny prostownik, falownik, układ sterowania, wyświetlacz i zestaw baterii. Zaletą takich systemów jest bardzo łatwa rozbudowa „na gorąco”, bez wykonywania połączeń kablowych, dużo mniejsza zajmowana powierzchnia (rozbudowa pionowo) oraz bardzo łatwy i pewny serwis polegający na wymianie uszkodzonego modułu UPS. Rama UPS, w którą wsuwane są moduły, jest jedynie elementem pasywnym, podobnie jak rozdzielnia elektryczna.
Koszt takich systemów w zestawieniu z systemami monoblokowymi 1 do 1 jest zawsze większy, jednak ze względu na łatwość rozbudowy i dopasowania się do aktualnego obciążenia, a także ogromną elastyczność i szybkość napraw, niejednokrotnie to rozwiązanie jest częściej wybierane przez inwestorów.
W przypadku systemów modułowych, jakie obecnie mnożą się na rynku, spotkać można poniższe wersje architektury z pojedynczymi punktami awarii.
System z centralnym by-passem
W tym przypadku każda szafa UPS, w której można zainstalować od kilku do kilkunastu modułów mocy ma jeden centralny moduł by-passu elektronicznego. Jego uszkodzenie powoduje upośledzenie działania całego systemu, który nie jest w stanie realizować wszystkich oczekiwanych od niego funkcji. Centralny system by-passu ma lepsze zdolności zwarciowe, charakteryzuje się też mniejszym prawdopodobieństwem awarii. Zadajmy sobie jednak pytanie – co, jeśli już awaria nastąpi? Zawodność systemu w szerszym spojrzeniu jest niezaprzeczalna.
System z centralną szyną DC („wspólna” bateria)
Większość modułów na rynku ma zdecentralizowany system ładowarek baterii, jednakże baterie są połączone szeregowo-równolegle, pracując na wspólną dla wszystkich modułów UPS szynę DC. Po pierwsze zwiększa to zagrożenie awarii, tak jak w przypadku systemów monoblokowych, a po drugie utrudnia skalowalność systemu, ponieważ zwiększanie czasu autonomii wiąże się z koniecznością dołączenia kolejnych baterii do pracującej szyny DC. Co więcej systemy ze wspólną baterią często charakteryzują się zmniejszoną żywotnością zestawów bateryjnych, gdyż zbyt duża liczba bloków połączonych szeregowo-równolegle powoduje większy rozrzut napięć na poszczególnych ogniwach i ich szybszą degradację. Taki system komplikuje również okresowe kontrolne rozładowania baterii, wymuszając zastosowanie zewnętrznych rozładownic i prostowników.
System z centralnym układem sterowania
System UPS z centralnym układem sterowania jest coraz rzadziej spotykanym rozwiązaniem. Jeden z modułów ma przyznane uprawnienia „master”, sterując resztą modułów. Uszkodzenie systemu master ma wpływ na działanie systemu i może spowodować zanik zasilania.
System z centralnym panelem kontroli
O dziwo to najczęściej spotykane na rynku rozwiązanie, ponieważ w tym zakresie zagadnienie niezawodoności jest bagatelizowane. Co prawda sam centralny wyświetlacz nie jest elementem krytycznym, jednak jego awaria może uniemożliwić wykonanie innych istotnych operacji przy urządzeniu do czasu jego naprawy np. transfer na by-pass, odczytanie alarmów czy pomiarów. Znowu możemy sobie zadać pytanie: czy wolimy mieć system z zdecentralizowanymi wyświetlaczami (na każdym panelu można odczytać wszystkie parametry systemu), czy też z jednym centralnym.
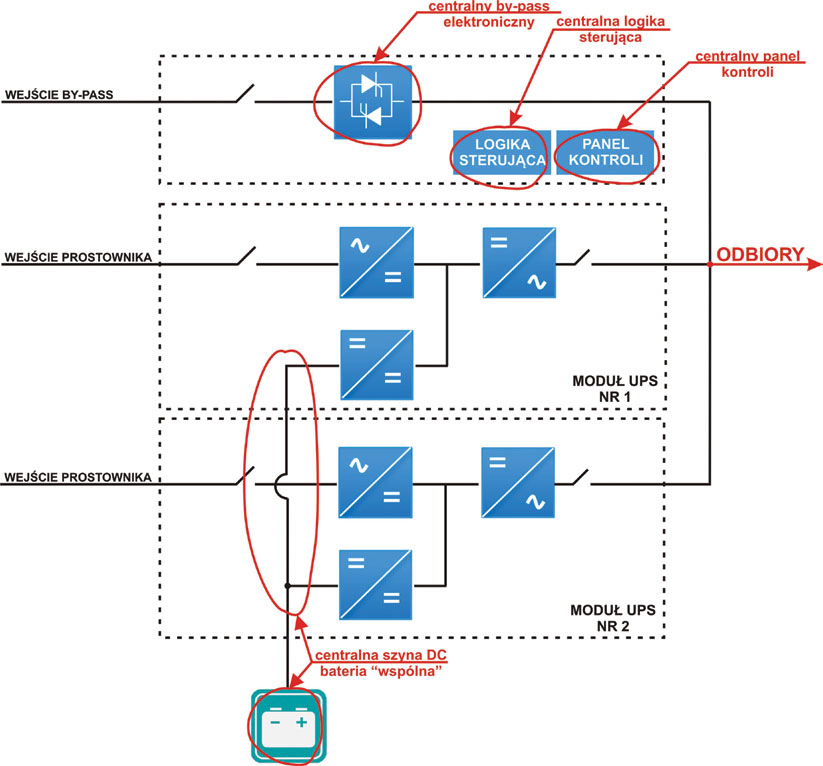 Rys. 4. Schemat systemu modułowego z pojedynczymi punktami awarii
Rys. 4. Schemat systemu modułowego z pojedynczymi punktami awariiReasumując, podczas doboru optymalnego rozwiązania dla naszego systemu, zawsze powinniśmy zwracać uwagę na eliminację pojedynczych punktów awarii. Poziom niezawodności ustala się na zasadzie pewnego kompromisu pomiędzy kosztami oraz prawdopodobieństwem wystąpienia awarii i jej skutków. Dlatego konieczna jest ścisła współpraca dostawcy systemów, projektanta i inwestora.
W branży Data Center tworzone są normy opisujące poziomy niezawodności systemów, np. podział TIER wg Uptime Institute, Amerykańska norma ANSI TIA-942, czy też nowa norma Europejska PN-EN 50600.
W części przypadków kompromisem są właśnie zdecentralizowane systemy modułowe typu DPA. Innym, bardzo często stosowanym, rozwiązaniem w Data Center jest zasilanie dwutorowe, które przy prawidłowym zaprojektowaniu może zapewnić eliminację pojedynczych punktów awarii w systemie elektroenergetycznym. W obrębie każdego z torów można również tworzyć systemy nadmiarowe, co jeszcze bardziej zabezpiecza nasze systemy w przypadku awarii. Nie można jednak popadać w obsesję redundancji, gdyż to prowadzi do nakręcenia ogromnej spirali kosztów, zwykle niepotrzebnych.
Mgr inż. Michał Redlich
Inż. Sprzedaży Data Center
FAST Group sp. z o.o.
www.fast-group.com.pl